OneStop: A 360-Participant English Eye Tracking Dataset with Different Reading Regimes#
📄 Paper | 📚 Documentation | 💾 Data | 🔬 More from LaCC Lab
Example#

Overview#
OneStop Eye Movements (in short OneStop) is a large-scale English corpus of eye movements in reading with 360 L1 participants, 2.6 million word tokens and 152 hours of recorded eye tracking data. The dataset was collected using an EyeLink 1000 Plus eyetracker (SR Research).
The dataset release includes Interest Area Reports (features aggregated at the word level), Fixation Reports (features aggregated at the level of fixations/saccades), raw data in edf and ASCII formats, and a detailed participant questionnaire. To facilitate analyses, we further provide precomputed text annotations: word length, frequency and surprisal (GPT2), as well as part-of-speech tags and syntactic dependency trees.
OneStop comprises four sub-corpora, one for each of the following reading regimes:
Ordinary reading for comprehension Download this data if you are interested in a general-purpose eye tracking dataset (like Dundee, GECO, MECO and others).
Information seeking
Repeated reading
Information seeking in repeated reading

We provide the entire dataset, as well as each of the sub-corpora separately.
Key Features#
Texts and Reading Comprehension Materials#
30 articles with 162 paragraphs in English from the Guardian.
Annotations of part-of-speech tags, syntactic dependency trees, word length, word frequency and word surprisal.
Each paragraph has two versions: an Advanced version (original Guardian text) and a simplified Elementary version.
Extensively piloted reading comprehension questions based on the STARC (Structured Annotations for Reading Comprehension) annotation framework.
3 multiple-choice reading comprehension questions per paragraph.
486 reading comprehension questions in total.
Auxiliary text annotations for answer choices.
Statistics#
Statistics of OneStop and other public broad-coverage eyetracking datasets for English L1.
Category |
Dataset |
Subjects |
Age |
Words |
Words Recorded |
Questions |
Subjects per Question |
Questions per Subject |
|---|---|---|---|---|---|---|---|---|
Reading Comprehension |
OneStop |
360 |
22.8±5.6 |
19,425 (Advanced) |
2,632,159 (Paragraphs) |
486 |
20 |
54 |
66 |
NA |
2,539 |
167,574 |
20 |
95 |
20 |
||
Passages |
Dundee |
10 |
NA |
51,502 |
307,214 |
NA |
10 |
NA |
14 |
21.8±5.6 |
56,410 |
774,015 |
NA |
14 |
NA |
||
84 |
NA |
2,689 |
225,624 |
0 |
0 |
0 |
||
46 |
21.0±2.2 |
2,109 |
83,246 |
48 |
46 |
48 |
||
Sentences |
69 |
26.3±6.7 |
61,233 |
122,423 |
78 |
69 |
78 |
|
18 |
34.3±8.0 |
15,138 |
272,484 |
42 |
18 |
42 |
||
43 |
25.8±7.5 |
1,932 |
81,144 |
110 |
43 |
110 |
‘Reading Comprehension’ are datasets with a substantial reading comprehension component over piloted reading comprehension materials. The remaining datasets are general purpose datasets over passages or individual sentences. ‘Words’ is the number of words in the textual corpus. ‘Words Recorded’ is the number of word tokens for which tracking data was collected. ‘NA’: data not available.
Controlled experimental manipulations#
Reading goal: ordinary reading for comprehension or information seeking.
Paragraph difficulty level: original Guardian article (Advanced) or simplified (Elementary).
Question identity: one of three possible questions for each paragraph.
Prior exposure to the text: first reading or repeated reading.
Experiment Structure#
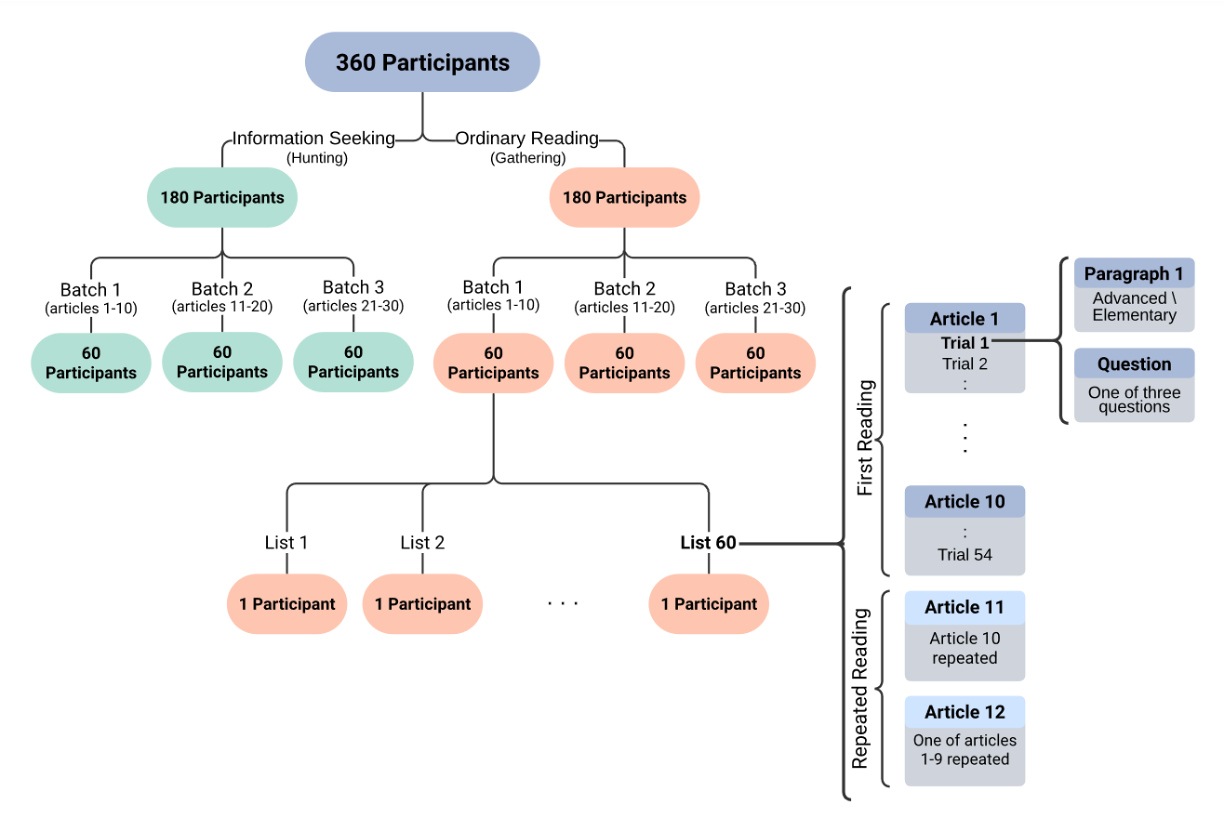
Each participant reads 10 Guardian articles paragraph by paragraph, and answers a reading comprehension question after each paragraph. After reading a 10-article batch, participants read two of the previously presented articles for a second time. Half of the participants are in an information seeking regime where they are presented with the question prior to reading the paragraph.
Trial Structure#
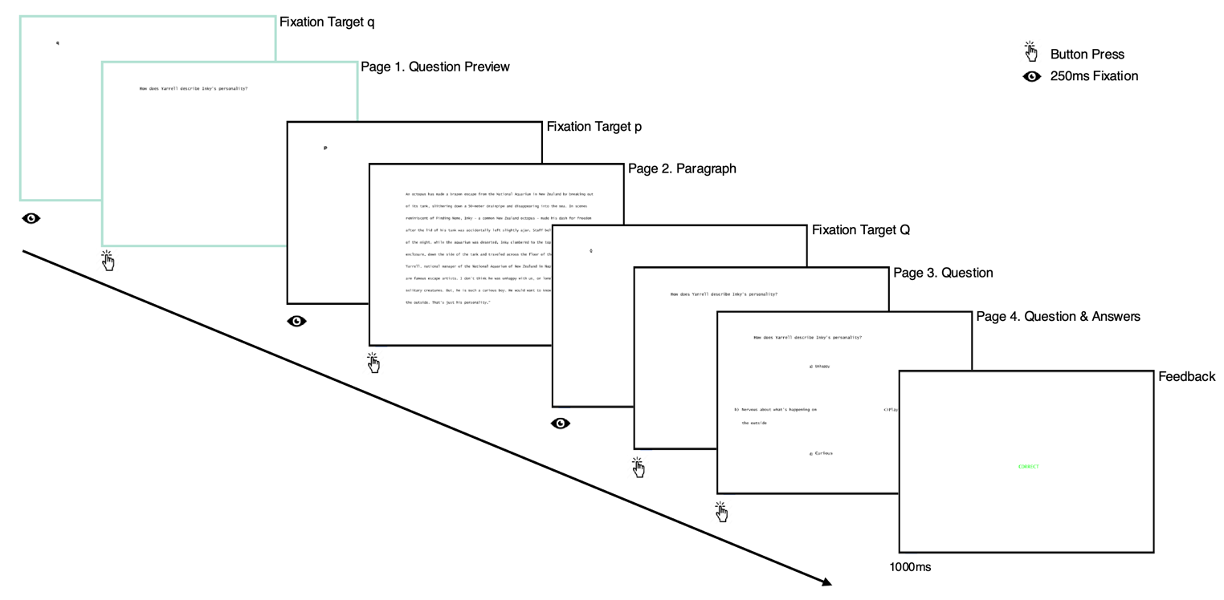
A single experimental trial consists of reading a paragraph and answering one reading comprehension question about it. Trials have the following Interest Periods, corresponding to pages in the experiment:
Question Preview (only in the information seeking regime) - the participant reads the question (self-paced).
Paragraph - the participant reads the paragraph (self-paced).
Question - the participant reads the question again (self-paced).
QA - retains the question, and also displays the four possible answers in a cross arrangement. Participants are then required to choose one of the answers and confirm their choice (self-paced).
Feedback - informs the participants on whether they answered the question correctly (presented for one second).
Pages presented only in the information seeking regime are depicted in green.
Overall, the dataset includes 19,438 regular trials, 9,720 in the information seeking regime and 9,718 in the ordinary reading regime. The dataset also includes 3,888 repeated reading trials, split equally between the two reading regimes.
Obtaining the Data#
Direct Download from OSF#
The data is hosted on OSF, and can be downloaded here.
We provide the possibility to download four sub-corpora with eye movement recordings from paragraph reading, one for each of the following reading regimes:
OneStop Ordinary Reading - download this data if you are interested in a general-purpose eye tracking dataset.
Two versions of the complete dataset:
OneStop All Regimes - paragraph reading for the entire dataset.
OneStop Full - complete trials for the entire dataset, divided into title, question preview, paragraph, question, answers, QA (question + answers) and feedback.
The raw data:
OneStop Raw - edf and ASCII files.
and the Metadata:
OneStop Metadata includes the participant questionnaire and experiment summary statistics.
Python Script#
The data can also be downloaded using the provided Python script. The script will download and extract the data files.
Basic usage to download the entire dataset:
Make sure you have Python installed.
If you don’t have Python installed, you can download it from here.
Get the Code
Open your terminal/command prompt:
Windows: Press
Win + R, typecmdand press EnterMac: Press
Cmd + Space, typeterminaland press Enter
Run this command to download the code:
git clone https://github.com/lacclab/OneStop-Eye-Movements.git
Move into the downloaded folder:
cd OneStop-Eye-Movements
Run the Download Script
Run this command to download the OneStop Ordinary Reading subcorpus:
python download_data_files.pyThe data will be downloaded to a folder called “data/OneStop”
Available options:
--extract: Extract downloaded zip files (default: False)-o, --output-folder: Specify output folder (default: “data/OneStop”)--mode: Choose dataset subcorporus to download (default: “ordinary”)Options: “onestop-full”, “onestop_all_regimes”, “ordinary”, “information_seeking”, “repeated”,”information_seeking_repeated”
Example usage to download the information-seeking subcorporus:
python download_data_files.py --mode information_seeking
pymovements integration#
OneStop is integrated into the pymovements package. The package enables easy download of the paragraph data for the complete dataset. The following code snippet shows how to download the data:
First, install the package in the terminal:
pip install pymovements
Then, use the following python code to download the data:
import pymovements as pm
dataset = pm.Dataset('OneStop', path='data/OneStop')
dataset.download()
This will download the data to the data/OneStop folder. You can also specify a different path by changing the path argument.
Documentation#
Data Files and Variables: Detailed information about the data files and variables in the reports.
Known Issues: Known issues with the dataset. If you identify an issue not listed here, please open a github issue specifying the problem.
Scripts: Scripts for data preprocessing and reproducing the analysis in the dataset paper.
Release Versions#
Releases correspond to the data release version.
Citation#
Paper: OneStop: A 360-Participant English Eye Tracking Dataset with Different Reading Regimes
@Article{Berzak2025,
author={Berzak, Yevgeni and Malmaud, Jonathan and Shubi, Omer and Meiri, Yoav and Lion, Ella and Levy, Roger},
title={{OneStop}: A 360-Participant English Eye Tracking Dataset with Different Reading Regimes},
journal={Scientific Data},
year={2025},
doi={10.1038/s41597-025-06272-2},
}
Dataset Uses Examples#
Text Simplification and Text Readability
Reading Comprehension
Fine-Grained Prediction of Reading Comprehension from Eye Movements (EMNLP 2024)
Bridging Information-Seeking Human Gaze and Machine Reading Comprehension (CoNLL 2020)
Information Seeking
Repeated Reading
Human-LLM Alignment and Memorization
License#
The eye tracking data, code, and anonymized participant questionnaire responses are released under a Creative Commons Attribution 4.0 International License. The underlying textual materials and auxiliary text annotations of OneStopQA are provided under the OneStopQA Creative Commons Attribution-ShareAlike 4.0 International License.
